AtendAI
Assistente de IA no WhatsApp que automatiza o atendimento interno de empresas, lendo a base de conhecimento e respondendo colaboradores em segundos, com custo por mensagem em centavos.
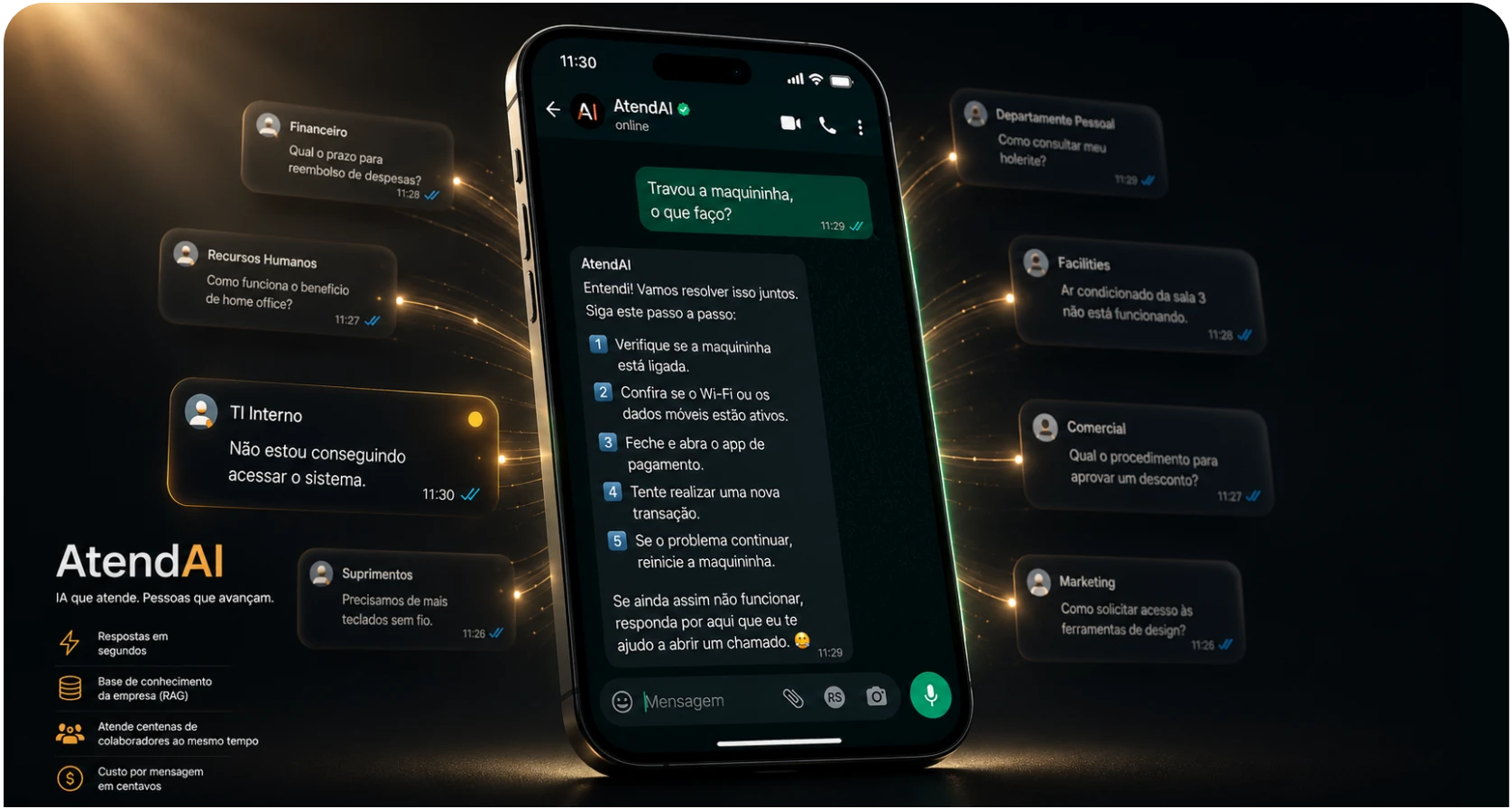
Assistente virtual de WhatsApp que centraliza e automatiza o atendimento interno de empresas que ainda dependem de mensagens diretas para tirar dúvidas de operação, RH, T.I. e suporte. Substituiu o atendimento manual e disperso de uma rede com mais de 400 colaboradores e 60 lojas, e em poucos meses foi adaptado para um segundo cliente — provando que a mesma arquitetura serve como produto multi-tenant.
O problema que ele resolve
Em qualquer empresa de médio porte, perguntas repetidas viram um gargalo silencioso. "Travou a maquininha", "qual o valor do vale alimentação", "como faço para devolver mercadoria" — e o setor de T.I. ou o RH passam o dia respondendo as mesmas coisas para pessoas diferentes, no privado, sem registro. O conhecimento da empresa fica preso na cabeça de quem responde, e cada nova contratação reabre o ciclo. O AtendAI entra exatamente nesse ponto: lê a base documentada da empresa, entende o que o colaborador está perguntando e devolve a resposta certa em poucos segundos, no canal que todo mundo já usa.
Como funciona para quem pergunta
O colaborador manda a dúvida no WhatsApp como se estivesse conversando com qualquer outra pessoa. Em segundos recebe uma resposta direta, com o passo a passo do procedimento, o setor responsável quando faz sentido escalar e até o e-mail de contato se o caso fugir do que está documentado. Pode mandar várias mensagens seguidas — o bot espera o raciocínio terminar, agrupa tudo e responde uma vez só, sem cortar a conversa em pedaços. E como o histórico da conversa é preservado, dá pra continuar perguntando "e se o problema for outro?" sem ter que reapresentar o contexto inteiro.
Como funciona para a operação
Setores que viviam afogados em mensagens recuperam tempo de trabalho real. O AtendAI cobre o que está documentado e só escala para o humano quando a pergunta sai do escopo da base. O T.I. ganha foco para tarefas estruturantes, o RH responde de uma vez para todo mundo via documento atualizado, e o atendimento interno vira um processo rastreável — cada interação fica registrada com a pergunta original, o que o bot recuperou da base e a resposta entregue. Atualizar a base é responsabilidade do próprio setor, com manual operacional próprio, sem depender de desenvolvedor para cada ajuste.
IA conversacional com custo de operação em centavos
O coração do AtendAI é uma arquitetura RAG (Retrieval-Augmented Generation) construída em FastAPI sobre LangChain, com modelo gpt-4o-mini da OpenAI e busca vetorial em ChromaDB. A escolha do modelo é deliberada: o gpt-4o-mini entrega qualidade de resposta de modelo grande a um custo por mensagem que cabe em centavos, viabilizando uso intensivo sem que a conta de IA vire um problema. Cada pergunta é reformulada considerando o histórico da conversa, busca os trechos mais relevantes da base por similaridade vetorial e gera a resposta ancorada nesse conteúdo — então o bot não inventa, responde com base no que a empresa documentou.
Direto no WhatsApp, sem app novo, sem custo de canal
O canal é o próprio WhatsApp, que o colaborador já tem instalado. Sem app proprietário, sem login, sem treinamento. A integração roda pela Evolution API conectada via Baileys, o que mantém o custo de envio próximo de zero — o cliente paga só o modelo de IA, não cada mensagem. Esse foi um critério de projeto desde o início: o bot precisava funcionar em escala numa rede com centenas de colaboradores sem que o custo crescesse linearmente com o volume de uso.
Multi-tenant validado em produção
A mesma arquitetura já roda para dois clientes em paralelo, com bases de conhecimento, prompts e instâncias completamente independentes. Para subir um novo cliente, basta trocar os documentos da base e os prompts — o código permanece intacto. A primeira implementação automatiza o atendimento interno de uma rede de tintas com 60 lojas e mais de 400 colaboradores; a segunda, uma revenda de alevinos, responde sobre 30 espécies de peixes para clientes externos. Mercados diferentes, mesmo motor.
Por baixo do capô
Backend Python rodando em containers Docker, FastAPI servindo a camada HTTP, LangChain orquestrando a chain RAG, ChromaDB persistindo o índice vetorial em disco e Redis cumprindo dupla função: histórico de conversa por sessão e buffer assíncrono que agrupa rajadas de mensagens curtas em uma única chamada à IA. Cada interação é registrada em log estruturado com a pergunta original, a query reformulada, os trechos recuperados e a resposta final — observabilidade pensada para diagnosticar qualquer caso em produção. Toda a operação cabe em poucos containers e pode ser instalada no servidor do próprio cliente, sem dependência de nuvem específica.
Se a sua operação ainda perde horas respondendo as mesmas perguntas no WhatsApp, ou se você quer transformar o conhecimento documentado da empresa em atendimento ativo 24 horas por dia, esse é exatamente o tipo de sistema que eu construo, ajusto e mantenho rodando.